監控主機與電腦連接線插口不匹配的解決方案

您好,您遇到的這個問題非常典型,是監控系統與電腦主機更新換代過程中常見的連接問題。別擔心,這通常不難解決。下面我將為您詳細說明幾種情況和對應的接線方法。
核心問題分析
您提到“監控主機”和“電腦主機”,這里需要先明確兩個設備:
- 監控主機(DVR/NVR):這是監控系統的核心,用來連接攝像頭、錄制和存儲視頻。它通常有一個專門的視頻輸出接口(如VGA或HDMI)連接到顯示器(或您的舊電腦主機?)。
- 電腦主機:您新更換的個人電腦。
您描述的“直接連到外面 接過來一條線連接電腦”,這條線很可能是從監控主機連接到舊電腦的線。這條線的作用通常是以下兩種之一:
- 視頻傳輸線:將監控主機的畫面顯示在舊電腦的顯示器上。
- 網絡線(網線):用于通過網絡訪問監控主機,在電腦上用軟件查看監控。
現在換了新電腦,插口不一樣,問題就出在這條連接線上。
第一步:確認連接線和接口類型
請先仔細觀察這條線兩端的接口形狀:
- VGA接口:梯形,通常為藍色,有15個針孔。這是老式顯示器接口。
- HDMI接口:扁平的梯形,內部有多個觸點。這是目前最主流的音視頻接口。
- DVI接口:長方形,內部有許多針腳或孔。
- 網線接口(RJ45):方口,類似電話線接口但更大,內部有8個銅芯觸點。
檢查您新電腦主機的背部提供了哪些視頻輸入接口(通常位于獨立顯卡或主板集成輸出區域)。
第二步:根據接口類型選擇解決方案
情況一:連接線是視頻線(VGA/HDMI/DVI)
如果這條線是用于顯示畫面的,那么它一端接監控主機的視頻輸出口,另一端本該接顯示器的。您舊電腦可能充當了顯示器的作用?更常見的情況是,這條線應該直接連接到一臺獨立的顯示器上,而不是電腦主機。
解決方案A(推薦):繞過電腦,直接連接顯示器。
將這條從監控主機出來的視頻線,直接連接到您家里任意一臺顯示器的對應接口上。這樣開機后,顯示器就會直接顯示監控主機的操作界面。這是最穩定、最直接的方法。
解決方案B:使用轉接頭或轉換線。
如果您必須將監控畫面接入新電腦主機,那您的目標可能是想用電腦的顯示器來顯示監控畫面,或者進行雙屏顯示。這時,您需要購買一個轉接頭或轉換線。
例如:
- 如果監控主機輸出是VGA,而新電腦只有HDMI輸入,您需要購買一個“VGA轉HDMI轉換器”(注意是帶芯片的主動式轉換器,不是簡單的轉接頭)。
- 如果兩頭都是HDMI,那就直接使用HDMI線連接即可。
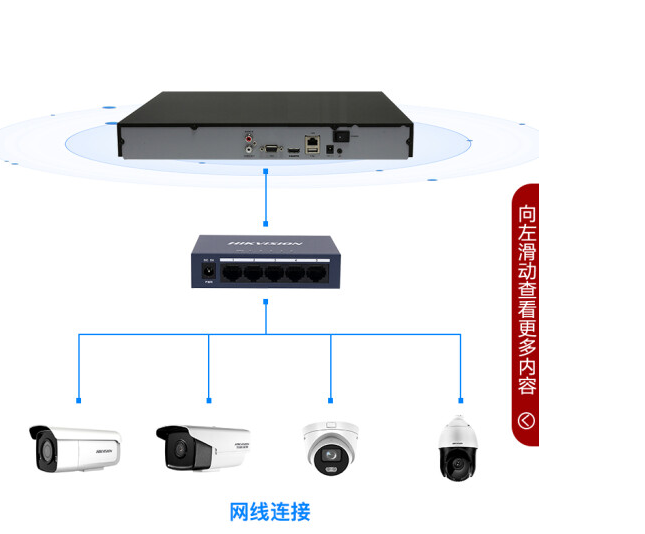
情況二:連接線是網線(RJ45)
如果這條線是網線,那么它一端接監控主機的網絡口(LAN口),另一端原本接在舊電腦的網絡口或路由器上。這種方式是通過局域網(IP地址)在電腦上訪問監控。
解決方案:使用網線直連或通過路由器。
1. 直連電腦:如果新電腦有網線接口(RJ45),直接將這條網線插入新電腦即可。然后需要在電腦上設置和舊電腦同一網段的IP地址,并安裝監控廠商提供的客戶端軟件或通過瀏覽器輸入監控主機的IP地址來訪問。
2. 連接路由器(更推薦):將監控主機的網線和您新電腦的網線,都插到同一個家庭路由器的LAN口上。這樣監控主機和電腦就在同一個網絡內,方便用軟件或網頁訪問,且不影響電腦正常上網。
第三步:通用且推薦的連接方案
對于大多數家庭監控系統,最穩定、最方便的配置方式是:
- 顯示部分:使用一根HDMI線(如果監控主機和顯示器都支持),直接將監控主機連接到一臺獨立的顯示器或電視機。這樣可以獲得最清晰、最穩定的實時監控畫面,用于回放、設置等操作。
- 遠程訪問部分:使用一根網線,將監控主機連接到您的家庭路由器。
- 電腦訪問:您的新電腦(無論臺式機還是筆記本)也連接到同一個路由器(可以通過WiFi或有線)。然后,在電腦上安裝監控設備自帶的客戶端軟件,或者直接在瀏覽器輸入監控主機的IP地址,就可以隨時隨地查看監控,實現遠程預覽、回放和下載,比直接連線更加靈活方便。
與建議
- 先確認線纜類型:是視頻線還是網線?
- 優先采用獨立顯示:如果只是為了看監控,用視頻線直接連顯示器/電視機是最簡單可靠的。
- 善用網絡功能:通過網線將監控主機接入路由器,再利用電腦或手機上的軟件進行網絡訪問,這才是發揮監控系統潛力的現代用法,也徹底擺脫了對電腦主機接口的依賴。
- 購買轉換設備:如果確實需要將特定接口的視頻信號接入新電腦的特定接口,去電商平臺搜索相應的“轉接頭”或“轉換器”即可,價格不貴。
希望以上詳細的步驟能幫您解決問題。如果還有不清楚的地方,可以補充說明連接線接口的具體形狀,我會為您提供更精確的建議。
如若轉載,請注明出處:http://m.zhongnar.cn/product/11.html
更新時間:2026-06-19 10:52:27